①get请求(搜索某些内容)
自动在百度上搜索关键词,获得搜索界面
#get请求
keywd="Python"
url="http://www.baidu.com/s?wd="+keywd #网址构造
print(url)
req=urllib.request.Request(url) #以请求的方式获取,网址
data=urllib.request.urlopen(req).read()
fh=open("C:/Users/admin/Desktop/a.html","wb") #以二进制写入html文件
fh.write(data)
fh.close()
#若搜索关键词为中文
keywd1="亚马孙"
keywd1=urllib.request.quote(keywd1) #利用quote对中文进行编码
url1="http://www.baidu.com/s?wd="+keywd1
req=urllib.request.Request(url1)
data=urllib.request.urlopen(req).read()
fh=open("C:/Users/admin/Desktop/a.html","wb") #二进制
fh.write(data)
fh.close()
②post请求(登录某些网站)
#post请求
import urllib.request
import urllib.parse
url="https://www.iqianyue.com/mypost/" #地址
login=urllib.parse.urlencode(
{"name":"1121640425@qq.com","pass":"123"}
).encode("utf-8") #登录数据
req=urllib.request.Request(url,login)
data=urllib.request.urlopen(req).read()
fh=open("C:/Users/admin/Desktop/a.html","wb")
fh.write(data)
fh.close()
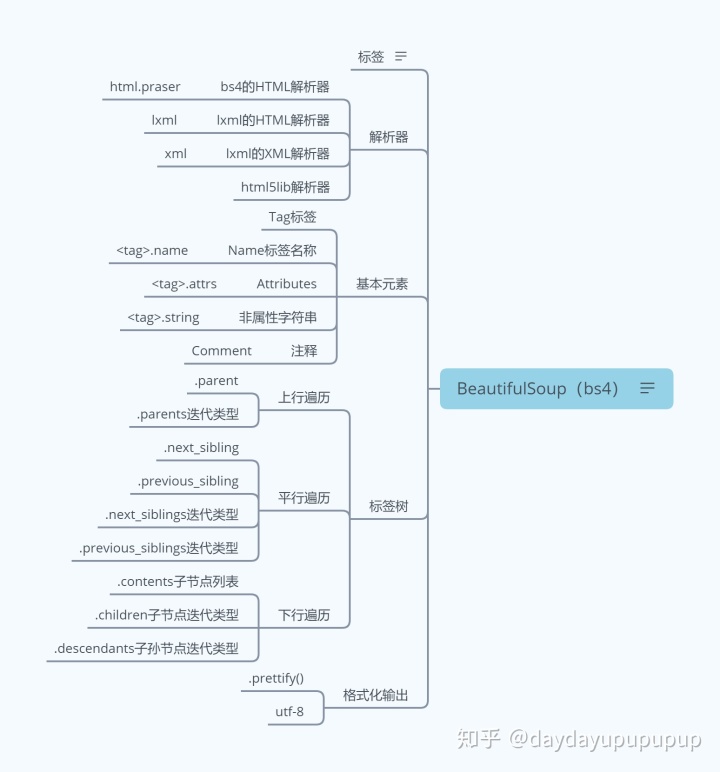
三、bs4库
功能:解析、遍历、维护检测树。
...
参考链接:
////
3.1支持的解析器
1.标准库:内置库、执行检测适中、文档容错能力强;
2.lxmlHTML解析器:速度快python爬虫代码大全,文档容错能力强(推荐);
3.lxmlXML解析器:速度快,唯一支持xml的检测器;
4.:最好的测评性、以检测器测验解析文档天外神坛,生成HTML5格式的文档。
具体用法:soup=(,="编码方式")
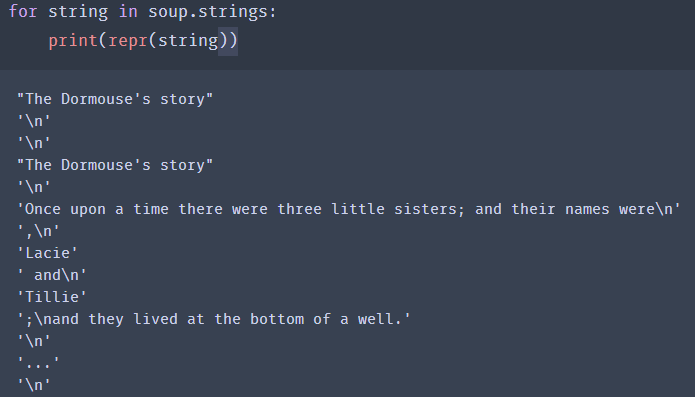
html = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie ,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.prettify()) #输出清晰的树形结构
Soup将复杂的HTML文档转化为检测结构,每个节点都是对象:
3.2基本用法
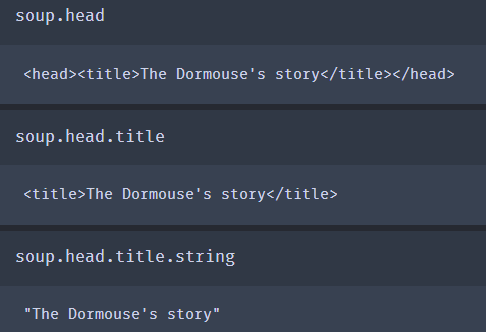
搜索文档树:tag.name_按顺序获得第一个标签
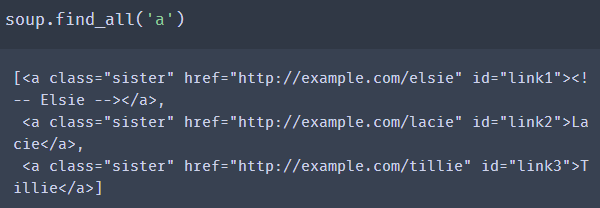
获取所有标签?
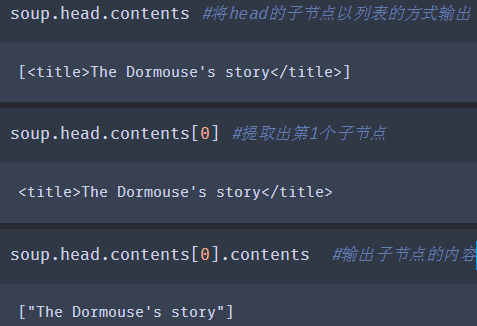
tag.可以将tag的子节点以列表方式输出
tag.,对tag的子节点进行循环
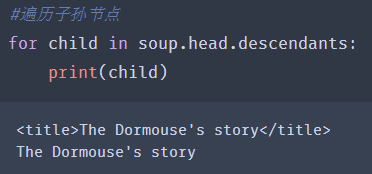
tag.,子孙节点
tag.python爬虫代码大全,获取tag(只有一个子节点)下所有的文本内容
迭代的测评找出所有的检测内容
soup.()#从文档中获取所有的文字内容
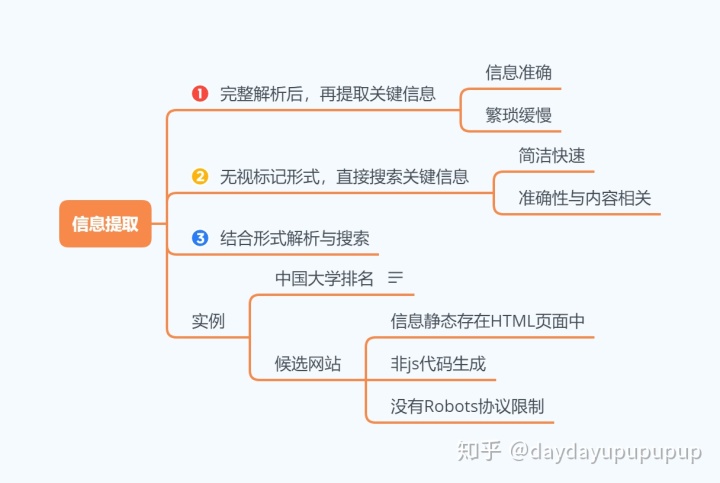
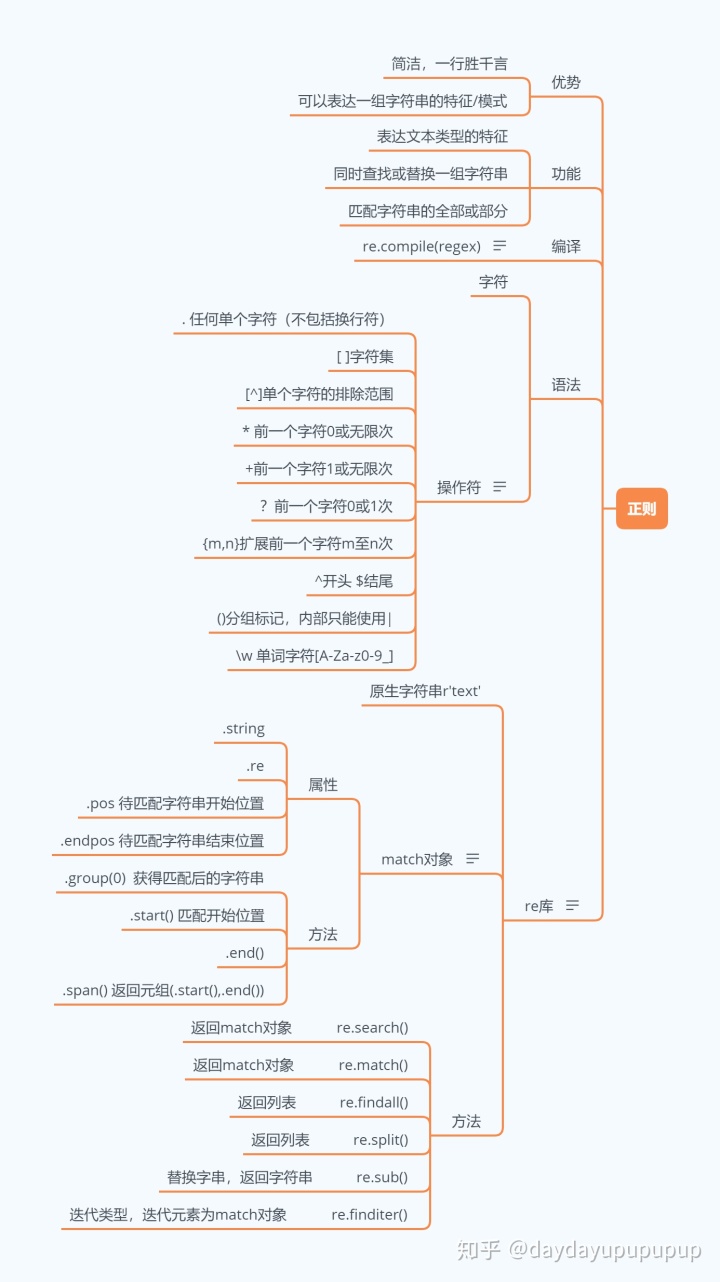
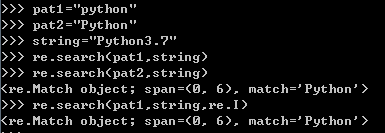
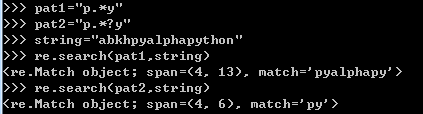
四、正则(信息提取)
import requests
from bs4 import BeautifulSoup
import bs4
#爬取信息
def getHtmlText(url):
try:
res=requests.get(url,timeout=30)
res.raise_for_status()
res.encoding=res.apparent_encoding
return res.text
except:
print("error")
return ""
#提取信息
def fillUnivList(ulist,html):
soup=BeautifulSoup(html,"html.parser")
for tr in soup.find("tbody").children:
if isinstance(tr,bs4.element.Tag): #检测tr标签的类型
tds=tr('td')
ulist.append([tds[0].string,tds[1].string,tds[2].string])
#打印信息
def printUnivList(ulist,num): #学习数量
tplt="{0:^10}\t{1:{3}^12}\t{2:^9}" #{}域,格式化输出
#表头
print(tplt.format("排名","学校","地址",chr(12288)))
for i in range(num):
u=ulist
print(tplt.format(u[0],u[1],u[2],chr(12288)))
print("Suc"+str(num))
#chr(12288)中文空格,解决中英文混排的问题
def mian():
uinfo=[]
url='http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html'
html=getHtmlText(url)
fillUnivList(uinfo,html)
printUnivList(uinfo,20)
mian()
         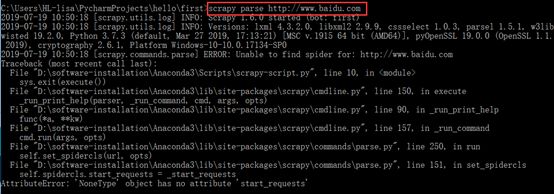   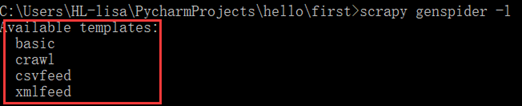 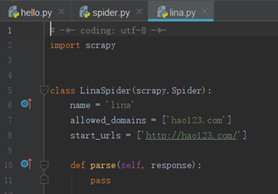  #作业:抓取csdn首页全部博文
import urllib.request
import re
url="http://blog.csdn.net/"
homepage=urllib.request.urlopen(url).read().decode('utf-8',"ignore")
print(len(homepage))
pat=',file)
print("--抓取成功--")
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
其他笔记: | 





 发表于 2022-3-1 10:59:35
发表于 2022-3-1 10:59:35