【介绍】轻量级网络架构的开源项目之前已经详细介绍过了。详情请看
,今天主要介绍CPU端最强的轻量级架构。本项目主要提供移动网络架构的基础工具,避免重复造轮子。未来,我们将为特定的视觉任务集成更多的移动网络架构。希望这个项目不仅能让初学者快速上手深度学习,还能更好地服务于科研、学术和工业研发社区。
(欢迎各位轻量级网络研究学者将自己工作的核心代码整理到本项目中,以促进科研社区的发展。我们会在里面注明代码作者~)
未来我们会持续更新模型轻量级处理的一系列方法,包括:剪枝、量化、知识蒸馏等。
地址:PP-LCNet:A CPU
:
近年来,随着特征提取模型能力的提升,出现了很多轻量级的网络架构,其中使用NAS进行搜索的网络架构也层出不穷。典型的是 FBNet 系列。但是移动端的很多轻量级算法的优化,都脱离了业界最常用的Intel CPU设备环境,模型加速慢。因此,在本文中,作者重新思考了在 Intel-CPU 上设计网络的轻量级模型元素。特别是,作者考虑了以下三个基本问题。
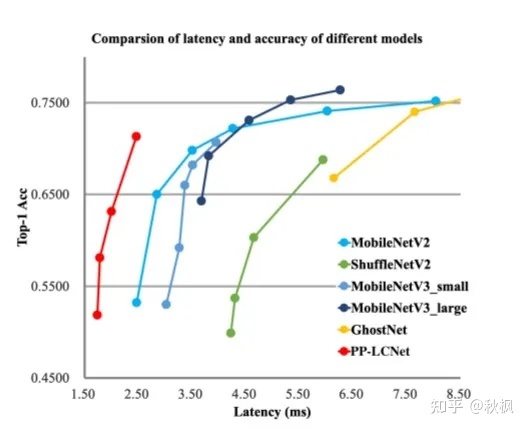
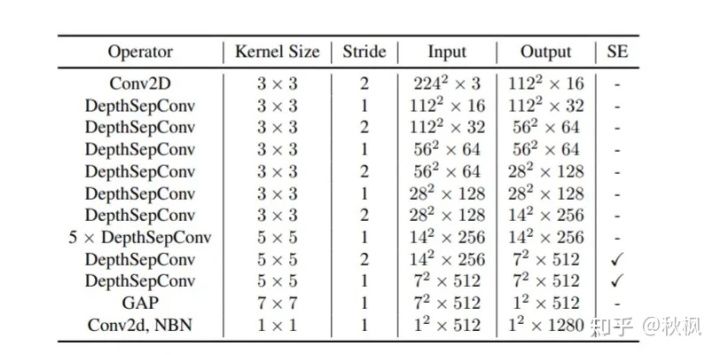
综合以上三个问题,本文总结了一系列在不增加推理时间的情况下提高准确率的方法,以及如何将这些策略有效地结合起来,以在准确率和速度之间取得更好的平衡。最后,提出了一种结合Intel-CPU端侧推理特性设计的轻量级高性能网络PP-LCNet。所提出的架构实现了比延迟精度更好的平衡。具体的网络架构如下:
主要解决方案:
使用 H-Swish 作为激活函数,性能大幅提升,而推理速度几乎没有变化。在网络的适当位置加入少量的 SE 模块,可以进一步提升模型的性能;实验表明,将 SE 置于模型尾部时,效果更好。因此,我们只将 SE 模块添加到靠近网络尾部的模块中,这具有更好的精度-速度平衡。根据实验演示结果:大的卷积核可以在一定范围内提升模型的性能,但是超过这个范围会损坏模型的性能。本文通过实验总结了一些较大的卷积核在不同位置的效果。类似于 SE 模块的位置,较大的卷积核在网络的中部和后部具有更明显的效果。比如5x5卷积。GAP之后使用更大的1x1卷积层;之后,分类层往往在GAP(--)之后直接连接天外神坛,但在轻量级网络中,GAP之后提取的特征不会进一步融合处理。如果后面使用更大的1x1卷积层(相当于FC层),GAP之后的特征不会直接经过分类层,而是先融合,融合后的特征会被分类。这样可以在不影响模型推理速度的情况下大大提高准确率。使用技术可以进一步提高模型的准确性。代码实现如下:GAP之后使用更大的1x1卷积层;之后,分类层往往在GAP(--)之后直接连接,但在轻量级网络中,GAP之后提取的特征不会进一步融合处理。如果后面使用更大的1x1卷积层(相当于FC层),GAP之后的特征不会直接经过分类层,而是先融合,融合后的特征会被分类。这样可以在不影响模型推理速度的情况下大大提高准确率。使用技术可以进一步提高模型的准确性。代码实现如下:GAP之后使用更大的1x1卷积层;之后主流的net快速开发框架,分类层往往在GAP(--)之后直接连接,但在轻量级网络中,GAP之后提取的特征不会进一步融合处理。如果后面使用更大的1x1卷积层(相当于FC层),GAP之后的特征不会直接经过分类层,而是先融合,融合后的特征会被分类。这样可以在不影响模型推理速度的情况下大大提高准确率。使用技术可以进一步提高模型的准确性。代码实现如下:GAP后提取的特征不会进一步融合处理。如果后面使用更大的1x1卷积层(相当于FC层),GAP之后的特征不会直接经过分类层,而是先融合主流的net快速开发框架,融合后的特征会被分类。这样可以在不影响模型推理速度的情况下大大提高准确率。使用技术可以进一步提高模型的准确性。代码实现如下:GAP后提取的特征不会进一步融合处理。如果后面使用更大的1x1卷积层(相当于FC层),GAP之后的特征不会直接经过分类层,而是先融合,融合后的特征会被分类。这样可以在不影响模型推理速度的情况下大大提高准确率。使用技术可以进一步提高模型的准确性。代码实现如下:使用技术可以进一步提高模型的准确性。代码实现如下:使用技术可以进一步提高模型的准确性。代码实现如下:
import torch
from light_cnns import lcnet_baseline
model = lcnet_baseline()
model.eval()
print(model)
input = torch.randn(1, 3, 224, 224)
y = model(input)
print(y.size())
实验结果展示
精彩内容待更新
欢迎大家给项目地址加star,我们会持续跟踪前沿论文的工作,如果项目复制整理过程中出现问题,欢迎在issue中提出!
地址: | 




 发表于 2022-1-8 19:05:04
发表于 2022-1-8 19:05:04