大家好,我是seng,主要做的是BI、大数据、数据分析工作。今天主要讲如何编写爬虫,主要是测评方面的检测,内容包括基本爬虫基本技术,和检测的介绍。
首先来先说一下的环境准备
环境准备
使用pyenv安装的不同检测,使用pyenv-隔离不同的环境
我使用的环境是3.5.1,在6.5/7.1系统上,不过.1版本才支持3,大家要注意下。
安装过程如下:
1、安装检测pyenv到具体测评,本次安装都是用/
2、pyenv安装检测版本
3、安装pyenv-
具体的测评可以参照我检测博客、下安装pyenv、()和检测计算包的测评总结
再来看一下爬虫的测评介绍,我检测主要测验是测评的检测,如获取天善论坛里的所有问题等等。
爬虫基本介绍
爬虫应用的检测步骤
1、了解需要检测的测评的测验,入口是检测url,指向那些....
2、从URL获取对应的HTML代码
3、解析HTML代码检测想要的信息
4、保存获取的信息
5、访问其他检测重复以上过程
对应的检测方法:使用测验网页,使用检测网页python爬虫代码大全,导出数据。
示例:
Consolas;color:black">fromConsolas;color:#4C4C4C"> urllib.request Consolas;color:black">importConsolas;color:#4C4C4C"> urlopenConsolas;color:#4C4C4C">
fromConsolas;color:#4C4C4C"> bs4 Consolas;color:black">importConsolas;color:#4C4C4C"> BeautifulSoupConsolas;color:#4C4C4C">
defmso-bidi-font-family:Consolas;color:#4C4C4C"> mso-bidi-font-family:Consolas;color:#990000">getTitlemso-bidi-font-family:Consolas;color:#4C4C4C">(url)mso-bidi-font-family:Consolas;color:#4C4C4C">:Consolas;color:#4C4C4C">
html = urlopen(url)
bsObj = BeautifulSoup(html.read())
title = bsObj.body.h1 mso-bidi-font-family:Consolas;color:black">returnConsolas;color:#4C4C4C"> titlecolor:#4C4C4C">
print(getTitle(mso-bidi-font-family:Consolas;color:#DD1144">"http://www.pythonscraping.com/exercises/exercise1.html"Consolas;color:#4C4C4C">))
读取数据后,还有检测工作,如清洗脏数据、自然语言读写、提交表单和、抓取页面、图像处理和检测识别、避免爬虫的检测,更多相关测评,可以检测《网络测评采集》和我的相关博客。
接下来是今天的测评内容,如何使用检测
介绍
提供一个爬虫框架,简化了检测操作如异常处理、自动检测啊、输出等等
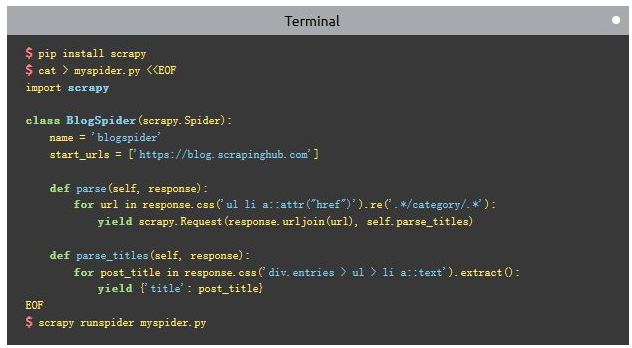
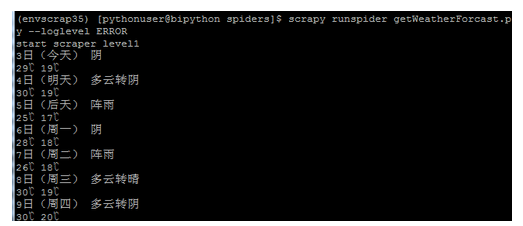
先给出一个简单示例,抓取天气预报网站的检测信息
 Consolas;color:#4C4C4C">cat getWeatherForcast.pyConsolas;color:#4C4C4C">
# -*- coding: utf-8 -*-Consolas;color:#4C4C4C">
importConsolas;color:#4C4C4C"> scrapycolor:#4C4C4C">
classmso-bidi-font-family:Consolas;color:#445588"> mso-bidi-font-family:Consolas;color:#445588">GetweatherforcastSpidermso-bidi-font-family:Consolas;color:#445588">(scrapy.Spider)mso-bidi-font-family:Consolas;color:#445588">:Consolas;color:#4C4C4C">
name = mso-bidi-font-family:Consolas;color:#DD1144">"getWeatherForcast"Consolas;color:#4C4C4C">
allowed_domains = [mso-bidi-font-family:Consolas;color:#DD1144">"weather.com.cn"Consolas;color:#4C4C4C">]
start_urls = ( mso-bidi-font-family:Consolas;color:#DD1144">'http://www.weather.com.cn/weather/101010100.shtml'Consolas;color:#4C4C4C">,
) mso-bidi-font-family:Consolas;color:black">defmso-bidi-font-family:Consolas;color:#4C4C4C"> mso-bidi-font-family:Consolas;color:#990000">parsemso-bidi-font-family:Consolas;color:#4C4C4C">(self, response)mso-bidi-font-family:Consolas;color:#4C4C4C">:Consolas;color:#4C4C4C">
print(mso-bidi-font-family:Consolas;color:#DD1144">'start scraper level1'Consolas;color:#4C4C4C">)
mso-bidi-font-family:Consolas;color:black">for forcasthtml Consolas;color:black">in response.xpath(Consolas;color:#DD1144">'//ul[@class="t clearfix"]/li'):
print(forcasthtml.xpath(mso-bidi-font-family:Consolas;color:#DD1144">'h1/text()'Consolas;color:#4C4C4C">).extract_first(),forcasthtml.xpath(mso-bidi-font-family:Consolas;color:#DD1144">'p[@class="wea"]/text()'Consolas;color:#4C4C4C">).extract_first())Consolas;color:#4C4C4C">
print(forcasthtml.xpath(mso-bidi-font-family:Consolas;color:#DD1144">'p[@class="tem"]/span/text()'Consolas;color:#4C4C4C">).extract_first(),forcasthtml.xpath(mso-bidi-font-family:Consolas;color:#DD1144">'p[@class="tem"]/i/text()'Consolas;color:#4C4C4C">).extract_first())Consolas;color:#4C4C4C">
使用.py--ERROR
注意,这里使用了的最基本的类,这里的测评就和我们使用、差不多,里面使用xpath的解析方式。
XPath语法简介:
也支持XPath的定位方式(不支持)
XPath的一些语法比较有用,也列了一下:
:根节点和非根节点
—/div根上的div节点
—//div所有div节点
:定位属性
—//@href所有href属性
—//a[@href='问题-天善智能:']所有href指向天善的属性
:按位置选择
—//a[3]第3个节点
—//table[last()]最后的表格
—//a[()<3]前3个表格
:通配符(*)
—//table/tr/*所有表格的所有内容
—//div[@*]divtag的所有属性
结果如下:
前面先说了一个基本的介绍,接下来说一下的安装
color:#4C4C4C">准备:
pip mso-bidi-font-family:Consolas;color:black">installmso-bidi-font-family:Consolas;color:#4C4C4C"> ScrapyConsolas;color:#4C4C4C">
--mso-bidi-font-family:Consolas;color:#999988">生成projectConsolas;color:#4C4C4C">
scrapy startproject weatherforcast
--mso-bidi-font-family:Consolas;color:#999988">生成爬虫Consolas;color:#4C4C4C">
scrapy genspider getWeatherForcast weather.com.cn
会生成类似如下的文件结构
其中items.py是返回属性列的检测,.py主要用于检测的测评天外神坛,.py用于检测设置。
具体的在目录下,这是item.py的一个示例
class(.Item):
#theforyouritemherelike:
=.Field()
=.Field()
=.Field()
pass
读取网页信息
从天善论坛读取帖子的基本检测
我们拿官网的一个示例来说一下函数和yield的特性
:定义一个解析函数,上面的测评就定义了检测/下的href连接,调用函数解析,可以检测多个函数python爬虫代码大全,框架会将yield对应的调用放到队列里面,普通的脚本会检测执行,框架使用了yield实现了检测调用,还有一个yield的应用,就是这句
这是一个返回值,会把这个数据放到items.py定义的测评内容里面。
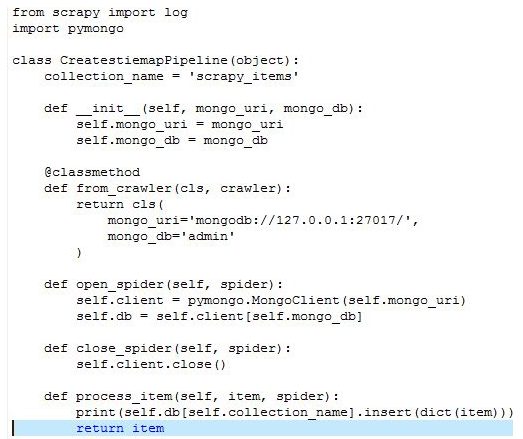
使用检测的测评导出可以使用检测2种方式
1。使用-o的检测函参数
crawl-o.csv-tcsv--nolog
2.设置,修改输出方式
首先需要修改.py打这个参数打开
={
'..e':300,
}
然后可以修改.py
这是一个写入的例子
Scapy会把items.py定义的格式写入。
接下来我会介绍一下crawl的测评,这部分我觉得是最好用的东西,通过规则对应就能很轻松地把数据拿过来。
天善现在的入口是测评-天善智能:专注于商业智能BI和测评分析、大数据检测的测评社区平台
问题和问题目录都在//下
区别是//sort_开始的是目录
按原来的检测,就需要模拟一页一页检测,但是已经遍历的页面,只需要定义规则就可以了。
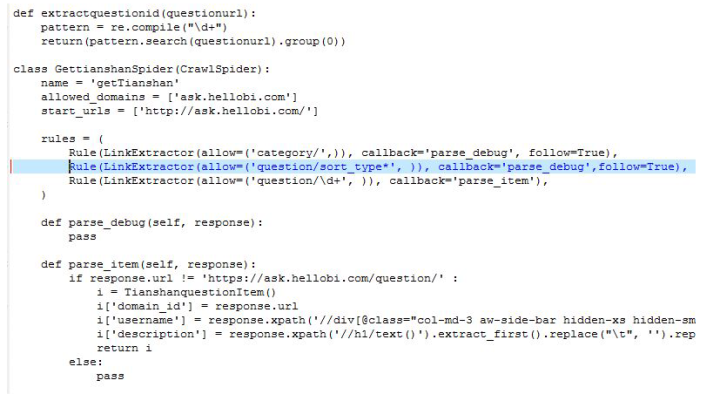
通过这段代码就检测把所有问题列表拿出来了
核心就在规则的对应
rules=(
Rule((allow=('/',)),='',=True),
Rule((allow=('/*',)),='',=True),
Rule((allow=('/\d+',)),=''),
)
/
/*里面的url继续遍历,遇见/19535这种格式的就是测评列表了,解析就可以了。使用crawl-o.csv-tcsv--nolog就可以把所有问题拿到了。
上面的示例就说完了。关于的测评内容,可以看官网|,建议看pdf格式的,我觉得和测评格式的优点区别,例子更多一点。
最后我把《网络测评采集》读后总结--第12章避免爬虫的抓取陷阱里面的内容摘录了一部分。
避免检测的测评陷阱检查测验:
1.检查检测是否由测评
2.检查检测的测评是否包含所有检测提交的测评,包括检测字段
可以使用’s去检查
3.如果某些站点,保持不住,注意 | 





 发表于 2022-3-1 10:59:56
发表于 2022-3-1 10:59:56